Tensorflow Dota Predictor¶
Google's new TensorFlow looks set to be the neural net library of the future, so I wanted to do a simple project to get to grips with it.
Predicting Dota matches is a fairly straight forward problem as far as neural nets go. Dota is a multiplayer online battle arena type game where two teams (Radiant and Dire) of 5 players try to destroy each others base. Each player can choose to play from a pool of 111 different characters (heros). Each character has a unique set of abilities and has a role to play in the game. This role is generally one of damage dealer, supportive, or something in between. The theory is that a successful team should be composed of characters whose roles and abilities work well together, and against the enemy team. The hope is that a neural would be able to pick up on these successful combinations and be able to predict the winner based on the characters picked by the players.
The problem definition then is fairly straight forward. The input is a binary table of the the characters chosen by each team and the output is the winner of match, the Radiant team or the Dire team. However, its clear that there will be a large irreducible error, since individual player skill generally trumps character choices.
Previous Work¶
Kevin Conley and Daniel Perry of Stanford University worked on a paper doing almost the same thing. Their paper focused on recommending characters for players to pick against an enemy line up. They train a logistic regression model to predict the winner of each match and use this to build a simple recommendation engine. Their best model gets to 69.8% validation accuracy. This seems like a solid result, its well above the 50% baseline, and supports the idea of large irreducible error as mentioned before. But lets try to replicate it anyway.
Note: When the authors gathered their dataset, there were 108 characters to choose from. Now there are 111, but I will continue using the out dated dataset for the sake of consistency.
import numpy as np
import pandas as pd
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import cross_val_score
#load and randomise data
dataset = pd.read_csv('dota_dataset.csv', index_col = 0)
dataset = dataset.take(np.random.permutation(len(dataset)))
#split dependent/independent variables
x = dataset.drop('radiant_win', axis=1)
y = dataset['radiant_win']
#print results
print 'Logistic Regression accuracy:', np.mean(cross_val_score(LogisticRegression(), x, y, scoring='accuracy', cv = 2))
print 'MultinominalNB accuracy:', np.mean(cross_val_score(MultinomialNB(), x, y, scoring='accuracy', cv = 2))
Something funnys going on in the paper, they report 69.8% accuracy using logistic regression but I have been unable to replicate it unless I restrict the dataset to the first ~20000 entries. This might suggest some error in the first ~20000 entries of the dataset. I compared logistic regression to my usual first choice for binary datasets, the multinomial Naive Bayes classifier. MultinomialNB seems to do much better over the whole dataset, and roughly in the ball park of the authors original model, so no harm done I guess.
When developing our neural net model, it will be useful to use MultinomialNB as a baseline.
Tensorflow Model¶
import tensorflow as tf
from sklearn.cross_validation import train_test_split
First split our dataset into training, validation and test sets
dataset, validation = train_test_split(dataset, test_size = 0.1)
train, test = train_test_split(dataset, test_size = 0.1)
print 'train:', train.shape, 'validation:', validation.shape, 'test:', test.shape
Initialise the TensorFlow session. InteractiveSession works much better for iPython Notebooks
sess = tf.InteractiveSession()
Now the placeholders. This are essentially all the information that you might want to pass into your graph. The reason for splitting up the x variable will be explained just a little later.
#input/output placeholders
x_dire = tf.placeholder("float", shape=[None, 108], name='x_dire')
x_radiant = tf.placeholder("float", shape=[None, 108], name='x_radiant')
y_ = tf.placeholder("float", shape=[None, 2], name='y_true')
#we'll use dropout layers for regularisation which need a keep probability
keep_prob1 = tf.placeholder("float", name='keep_prob1')
keep_prob2 = tf.placeholder("float", name='keep_prob2')
#there doesn't seem to be any other way to differenciate train and validation summaries for TensorBoard
loss_name = tf.placeholder("string", name='loss_name')
accuracy_name = tf.placeholder("string", name='accuracy_name')
The following function creates a fully connected layer with the matching weights/biases
def fc_weight_bias(in_size, out_size):
initial_weight = tf.truncated_normal([in_size, out_size], stddev=0.2, mean=0.0)
initial_bias = tf.constant(0.1, shape=[out_size])
return tf.Variable(initial_weight), tf.Variable(initial_bias)
Now I'll explain the network architecture.
Since there are two teams in Dota and we intuitively want to network to first learn about the composition of each team, then pit them against each other, it makes sense to split the network in two at the bottom. One neural net to learn about the Radiant team, and another to learn about the Dire team, and combine them later to predict the winner.
But a good team on the Radiant side is still be a good team on the Dire side. It makes sense that if our neural net model learns that a certain combination of characters on one side is a good it should transfer that knowledge to the other side. How do we do this? We make both sides use the same weights! This solves both problems. It allows the neural net to concentrate on learning what makes anyone one side effective at the lower layers and leaves how to combine that information to the higher levels. Its a nice hierarchical structure, which is exactly what neural nets are good at.
We're going to project the output to 2 columns, which i'll explain below.
#first hero layer
with tf.name_scope("hero_layers_1") as scope:
W_hero1, b_hero1 = fc_weight_bias(108,80)
#note that dire layer and radiant layer use the same weights and biases
dire_layer1 = tf.nn.relu(tf.matmul(x_dire, W_hero1) + b_hero1)
radiant_layer1 = tf.nn.relu(tf.matmul(x_radiant, W_hero1) + b_hero1)
#second hero layer
with tf.name_scope("hero_layers_2") as scope:
W_hero2, b_hero2 = fc_weight_bias(80,80)
#again, dire and radiant use the same weights and biases
dire_layer2 = tf.nn.relu(tf.matmul(dire_layer1, W_hero2) + b_hero2)
radiant_layer2 = tf.nn.relu(tf.matmul(radiant_layer1, W_hero2) + b_hero2)
#now concatenate the dire and radiant team outputs
with tf.name_scope("hero_layers_concat") as scope:
dire_radiant_concat = tf.concat(1, [dire_layer2, radiant_layer2])
dire_radiant_drop = tf.nn.dropout(dire_radiant_concat, keep_prob1)
h_drop1 = tf.nn.dropout(dire_radiant_drop, keep_prob1)
with tf.name_scope("hidden_layer_1") as scope:
W_hidden1, b_hidden1 = fc_weight_bias(160,120)
h_hidden1 = tf.nn.relu(tf.matmul(h_drop1, W_hidden1) + b_hidden1)
h_drop2 = tf.nn.dropout(h_hidden1, keep_prob2)
with tf.name_scope("hidden_layer_2") as scope:
W_hidden2, b_hidden2 = fc_weight_bias(120,75)
h_hidden2 = tf.nn.relu(tf.matmul(h_drop2, W_hidden2) + b_hidden2)
with tf.name_scope("hidden_layer_3") as scope:
W_hidden3, b_hidden3 = fc_weight_bias(75,25)
h_hidden3 = tf.nn.relu(tf.matmul(h_hidden2, W_hidden3) + b_hidden3)
with tf.name_scope("output_layer") as scope:
W_hidden4, b_hidden4 = fc_weight_bias(25,2)
y = tf.nn.softmax(tf.matmul(h_hidden3, W_hidden4) + b_hidden4)
And since we're using TensorFlow, we get a graph representation of our net for free!
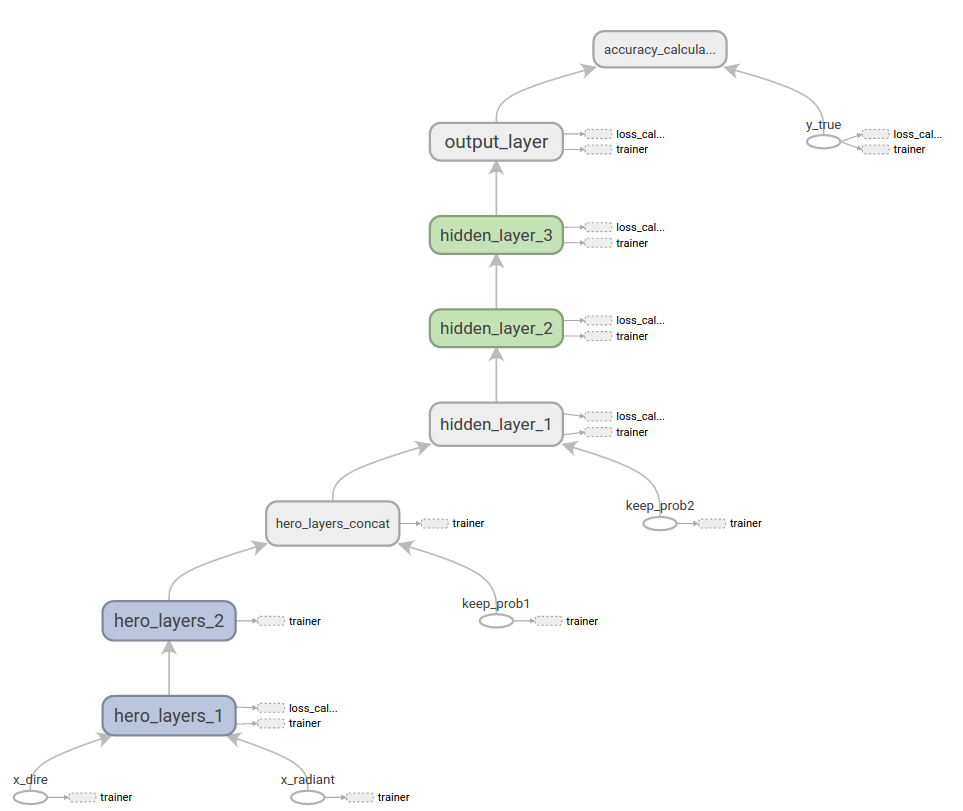
Now after propagating through the network, we need to analyse our result. As mentioned, our result will be project to two columns instead of just one. We'll one-hot encode the winning team so that one column represents a win for the Radiant and the other a win for the Dire. I got better preformance from the network doing softmax + cross-entropy on the two columns rather than sigmoid + binary cross-entropy on one column. I believe this might be because the network gets two points of information this way rather than one.
To improve generalisation, I regularise the network by adding the sum of the l2 norms of all the weights and biases to the loss value. I found this helped a lot. Mean loss is used as a reporting metric to compare training and validation loss.
For training, I used the Adam Optimizer. The best introductory resource I've found for choosing the right optimizer is by Sebastian Ruder here. As he suggests, using an optimizer that implements adaptive learning rates for each parameter is usually advisable given sparse data. Since some heros are picked much less frequently than others, the Adam optimizer is a good choice here.
Finally, for accuracy prediction, we pair off the prediction with the ground truth values to and check if they're equal.
with tf.name_scope("loss_calculations") as scope:
cross_entropy = -tf.reduce_sum(y_ * tf.log(y + 1e-8))
weights_sum = tf.add_n([tf.nn.l2_loss(variable) for variable in tf.all_variables()])
loss = cross_entropy + weights_sum
mean_loss = tf.reduce_mean(loss)
with tf.name_scope("trainer") as scope:
train_step = tf.train.AdamOptimizer(0.0001).minimize(loss)
with tf.name_scope("accuracy_calculations") as scope:
correct = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct, "float"))
Tensorflow allows us to generate some nice visualisations in Tensorboard using summary objects
#summarize the accuracy and loss
accuracy_summary = tf.scalar_summary(accuracy_name, accuracy)
mean_loss_summary = tf.scalar_summary(loss_name, mean_loss)
#summarize the distribution of output values
y_hist = tf.histogram_summary("y", y)
#gather all summaries
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("logdir", sess.graph_def)
Now that we're just finished setting up our model, initialize all the variables we created
sess.run(tf.initialize_all_variables())
We'll create a helper function to help create the various data feeds we need
def get_data_feed(dataset, kp1=1.0, kp2=1.0, loss_str='loss', accuracy_str='accuracy'):
radiant_data, dire_data = dataset.ix[:,:108], dataset.ix[:,108:216]
winners = pd.get_dummies(dataset['radiant_win'])
return {
x_radiant: radiant_data,
x_dire: dire_data,
y_: winners,
loss_name: loss_str,
accuracy_name: accuracy_str,
keep_prob1: kp1,
keep_prob2: kp2
}
train_feed = get_data_feed(train, loss_str = 'loss_train', accuracy_str = 'accuracy_train')
validation_feed = get_data_feed(validation, loss_str = 'loss_validation', accuracy_str = 'accuracy_validation')
test_feed = get_data_feed(test, loss_str = 'loss_test', accuracy_str = 'accuracy_test')
And a helper function to generate the mini-batches for our dataset
def get_batches(dataset, batch_size=512):
#randomise before every epoch
dataset = dataset.take(np.random.permutation(len(dataset)))
i = 0
while i < len(dataset):
yield dataset[i : i + batch_size]
i = i + batch_size
for i in range(100):
for mini_batch in get_batches(train):
mini_batch_feed = get_data_feed(mini_batch, 0.5, 0.5)
train_step.run(feed_dict = mini_batch_feed)
#log every epoch
train_loss = loss.eval(feed_dict = train_feed)
validation_loss = loss.eval(feed_dict = validation_feed)
train_accuracy = accuracy.eval(feed_dict = train_feed)
validation_accuracy = accuracy.eval(feed_dict = validation_feed)
train_summary_str = merged.eval(feed_dict = train_feed)
validation_summary_str = merged.eval(feed_dict = validation_feed)
writer.add_summary(train_summary_str, i)
writer.add_summary(validation_summary_str, i)
print("epoch %d, loss: %g, train: %g, validation: %g"% (i, train_loss, train_accuracy, validation_accuracy))
writer.close()
After 100 or so epochs, it looks like the network has more or less converged. We also get some more pretty graphs for free from TensorBoard. Although its kinda annoying how there isn't currently anyway to put the training and validation loss plots on the same graph.
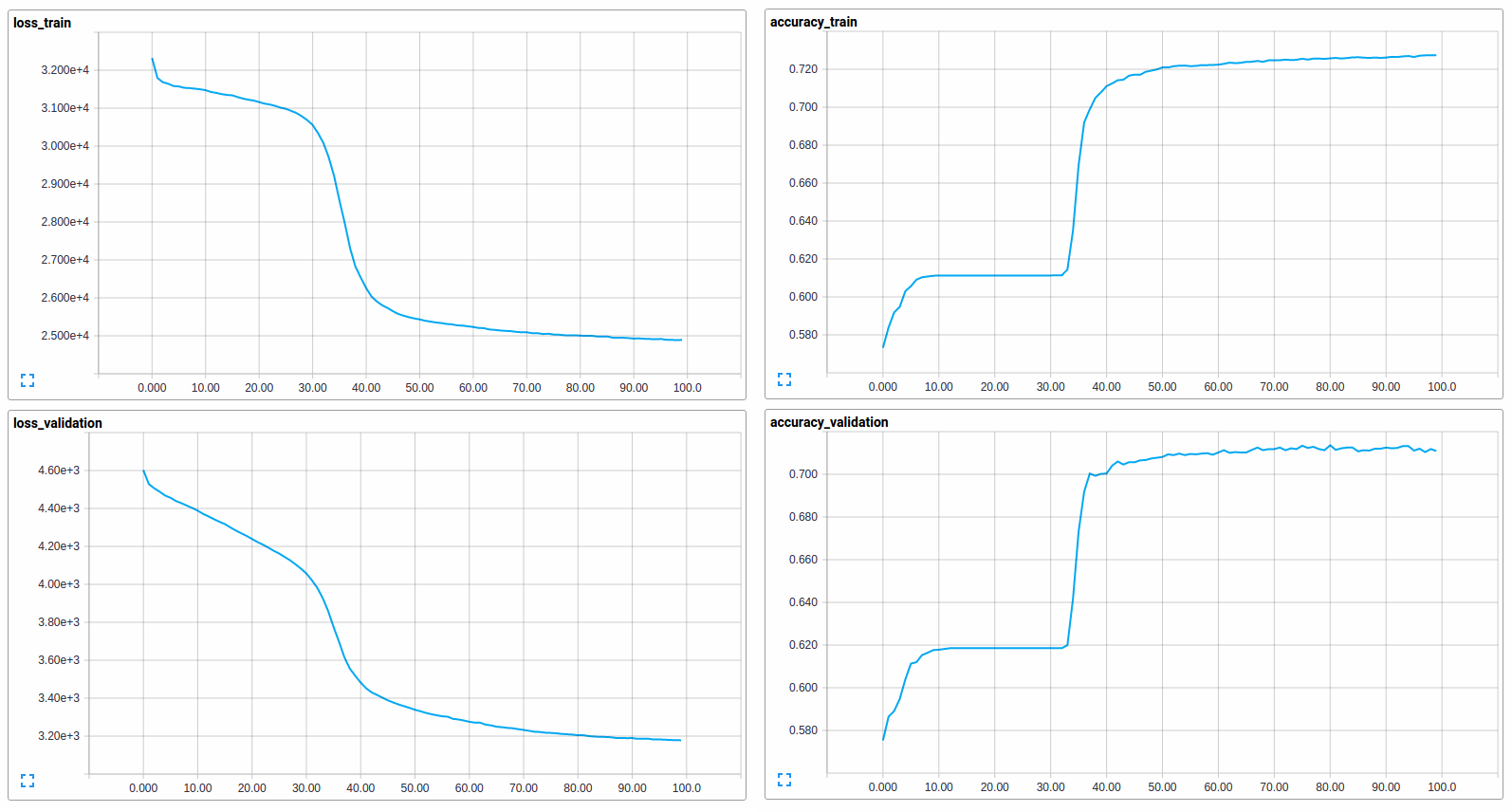
Finally, only after we've convinced ourselves that our model is pretty much finalised, do we get to peek at the test score.
accuracy.eval(feed_dict=test_feed)
Neat, 72.21% test accuracy! Earlier, the MultinominalNB model got to about 71.5% accuracy. Before drawing the conclusion that our model is definitely better though, I think there are two things worth noting.
The first is that there is a good chance we got kinda lucky with our test data and that it was relatively easy to predict. Its quite unusual to get a higher test score than validation score. This could be rectified by doing some proper cross validation, i.e repeatedly choosing different training, validation and test sets and seeing how the model preforms. But this is a bit of a chore when you have to worry about long training times.
The second thing worth noting is the vast difference between the complexity of building each model. It is far from insignificant that the MultinominalNB model could be built and cross validated in one line of code. Its clear which one would be easier to maintain and debug. The added complexity of the neural net also brings the relative unexplainability of each decision. The naive bayes model can be analysed using some bayesian statistics, but analysing neural nets and understanding why they arrive at the answers they do is still an active area of research.
Because of the points above, after all this, I think its fair to declare the one-line MultinominalNB model the winner. Either way, I learned a lot while writing this up which was always my primary goal.